
Used Car Price Model (Part 1) - Web Scraping
The Toyota Corolla is the vanilla bean of the icecream world - reliable, fuel efficient and fast enough to keep up with traffic. While it might not stir emotions of power and adrenaline, the car will make a good case study for a used-car price model. It is one of Toyota's best selling models, has a long history in Australia and so there are plenty around for sale.
The goal of this project will be to create a model to predict the price of a used car. It will use adverts found on gumtree.com.au, which is Australia's home of used cars. It will be split into 3 parts:
- Building a webscraper using Requests and BeautifulSoup
- Cleaning the data with pandas and extracting additional features
- Building a predictive model
Let's begin.
Requests and BeautifulSoup
Requests is a library that allows us to make HTTP requests. The response from this request can be parsed using BeautifulSoup, which will allow us to access specific HTML tags. We'll create a simple function to return the parsed HTML (or soup) from a URL.
from bs4 import BeautifulSoup
import requests
def get_soup(url):
r = requests.get(url)
return BeautifulSoup(r.text, 'html.parser')
The soup object that is returned has methods that can be called, such as finding all the h2 tags.
soup = get_soup('http://gumtree.com.au')
soup.find_all('h2')
Constructing the Search URL
Heading on over to the Gumtree Cars, we can input the initial search for a Toyota Corolla.

After hitting the search button, the URL we end up on is
We can see that toyota and corolla have ended up in the URL. If we wanted to search for a Ford Ranger, we could switch out "toyota" with "ford" and "corolla" with "ranger" and would most likely end up on the correct page.
An alternative method that Gumtree allows is add query strings to the URL, which take the form of ?name=value&name2=value2. For example, we can add ?pageSize=96 to the end of the URL to display 96 car ad results per page. It can sometimes take a bit of digging around in a website's source to find the appropriate parameter names. Some of the ones for Gumtree are in the construct_search_url() function below.
Firstly, we'll create a namedtuple to store the car search parameters for a Corolla. I'm using a lower limit of $1,000 to avoid capturing any wrecks and this will be limited to Perth with a search radius of 200km.
from collections import namedtuple
Car = namedtuple('Car', 'make model year_begin year_end ' + \
'min_price max_price location radius')
corolla = Car(
make='toyota',
model='corolla',
year_begin=1990,
year_end=2020,
min_price=1000,
max_price=40000,
location=3008507, # locationId for Perth 6000
radius=200, # Search radius in km
)
The function below creates a dictionary for the query strings. An instance of the Car namedtuple is passed to the function which then returns the URL.
def construct_search_url(car):
"""Return the gumtree search url using the Car namedtuple"""
params = {
'pageSize': 96, # Results per page, options are 24, 48 and 96
'attributeMap[cars.carmake_s]': car.make,
'attributeMap[cars.carmodel_s]': car.make + '_' + car.model,
'attributeMap[cars.caryear_i_FROM]': car.year_begin,
'attributeMap[cars.caryear_i_TO]': car.year_end,
'minPrice': car.min_price,
'maxPrice': car.max_price,
'locationId': car.location,
'radius': car.radius,
}
return 'https://www.gumtree.com.au/c18320?' + \
'&'.join([f'{k}={v}' for k,v in params.items()])
url = construct_search_url(corolla)
print(url)
We can then feed this URL into the get_soup function that was created before.
soup = get_soup(url)
Multiple Pages of Results
At the time of writing this, there were 261 search results. I've already set the page limit to 96 (maximum). We're going to need to iterate through multiple pages of results. On a web browser, this is normally done through the navigation panel.

<a class="page-number-navigationlink **page-number-navigationlink-last** link link--base-color-primary link--hover-color-none link--no-underline" href="/s-cars-vans-utes/perth-perth/carmake-toyota/carmodel-toyota_corolla/caryear-19902020/page-3/c18320l3008507r200?price=1000.0040000.00">Last page</a>
The "Last page" link uses a CSS class named page-number-navigation__link-last, which we can use as a reference when calling the find() method on the soup object.
result = soup.find('a', class_='page-number-navigation__link-last')
print(result)
The total number of pages is the integer following the /page- part of the URL. In this case, page-3. We can use regex to obtain this value.
import re
re.search('(?<=page-)\d*', result['href']).group()
We can put this into a function. In the case that there is only 1 page of results the function will return None.
def get_num_pages(soup):
"""Return the total number of pages of search results. If the 'Last page'
navigation link doesn't exist, return None"""
result = soup.find('a', class_='page-number-navigation__link-last')
if result:
num_pages = re.search('(?<=page-)\d*', result['href']).group()
return int(num_pages)
else:
return None
Collecting all the Soups
We can now iterate through the pages and collect a list of all the soup objects. An easy way to navigate through the pages is to add &pageNum= to the end of the URL. After each request, we will sleep 30-60 seconds to be respectful to Gumtree (and avoid being flagged as a bot).
In the case that get_num_pages returns None (ie there is only 1 page of results), then there will be no need for any additional page requests.
import random
import time
num_pages = get_num_pages(soup)
soup_list = [soup]
if num_pages:
for i in range(2,num_pages+1):
print(f'Scraping page {i} of {num_pages}')
soup = get_soup(url + '&pageNum=' + str(i))
soup_list.append(soup)
print('Sleeping... \n')
time.sleep(random.randint(30,60))
Unique Identifiers
Going back to a web browser and inspecting elements on the search results page, we can see that each advert is a link.
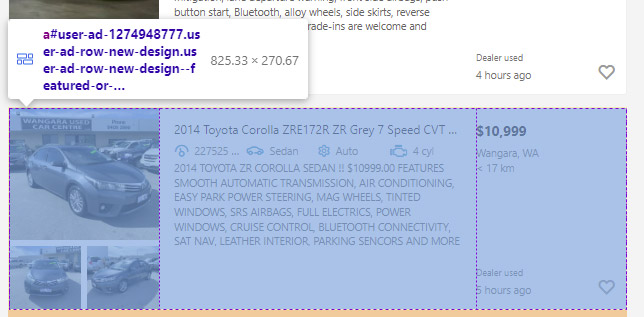
Each advert has a unique 10 digit numeric identifier. If we look at the source, we can see this is located at the end of each URL and also in the id as "user-ad-XXXXXXXXXX"
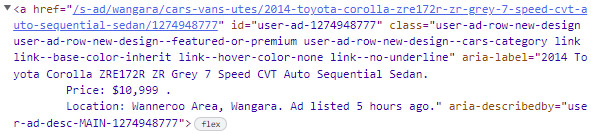
A quick method will be to use regex to find all the 10 digit identifiers. The below function will return a set of ID's found in the soup.
def get_ad_ids(soup):
ids = re.findall(r'(?<=user-ad-)\d{10}', str(soup))
return set(int(id_) for id_ in ids)
ad_ids = get_ad_ids(soup_list)
print(f'Number of ad identifiers found: {len(ad_ids)}')
Great, there are 261 unique ad id's, which matches the number found before. We can use the ad id to point directly to the ad listing using the base URL gumtree.com.au/s-ad/ followed by the 10 digit code.
ad_ids = list(ad_ids)
print(f'First ad id: {ad_ids[0]}')
Car Listing Details
Opening up the first ad in a browser, which would be gumtree.com.au/s-ad/1293184000, there's a lot of information we want to collect. There's the ad title, price, location and information in the details section.
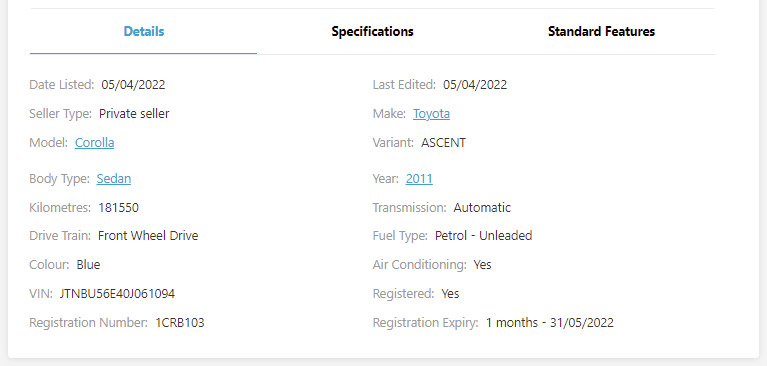
The below function takes the ad id and returns a dictionary of the details.
def get_car_details(id_):
"""Return a dictionary of car details from the advert page"""
soup_ad = get_soup('http://gumtree.com.au/s-ad/' + str(id_))
title = soup_ad.title.text
state = re.search('(?<="locationState":")\w+', str(soup_ad))
details = {
'Ad ID': id_,
'Ad Title': re.search('.*(?= \| Cars,)', title).group(),
'Price': soup_ad.find('span', class_='user-ad-price__price').text,
'Description': soup_ad.find('div', class_='vip-ad-description__content').text,
'State': state and state[0],
'Area': re.search('(?<=Gumtree Australia )[\w\s]+(?= - )', title).group(),
'Suburb': re.search('(?<= - )[\w\s]+(?= \| \d{10})', title).group(),
}
car_details_list = soup_ad.find_all('li', class_="vip-ad-attributes__item")
for elem in car_details_list:
k = elem.find('span', class_='vip-ad-attributes__value')
v = elem.find('span', class_='vip-ad-attributes__name') or \
elem.find('a', class_='vip-ad-attributes__name')
if k and v:
details[k.text] = v.text
return details
first_ad = get_car_details(1293184000)
first_ad
We will now iterate through all the id's, storing the results in a pandas dataframe.
import pandas as pd
corolla_data = pd.DataFrame([])
for ad_id in ad_ids[]:
details = get_car_details(ad_id)
df_details = pd.DataFrame(details, index=[0])
corolla_data = pd.concat([corolla_data, df_details], join='outer', sort=False)
time.sleep(random.randint(30,60))
corolla_data.head()
And that's a wrap. Save the dataframe to a csv and we'll continue this in the next part, where we will begin to clean up the data and extract additional features.
corolla_data.to_csv('corolla_data.csv', index=False)